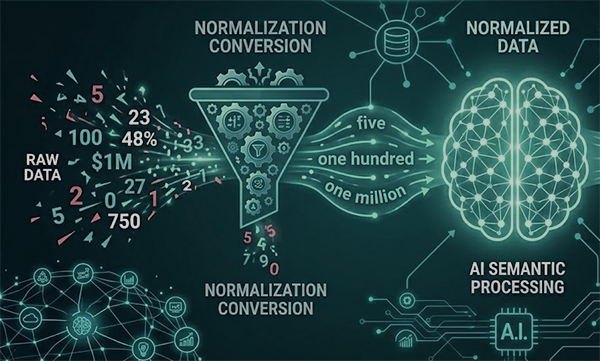
In the world of Artificial Intelligence, data is everything. However, raw data is often “noisy.” For an AI model, the digit “7” is a mathematical symbol, but in a sentence, it represents the word “seven.” This distinction is the heart of Text Normalization, a crucial step in Natural Language Processing (NLP). Whether you are training a Large Language Model (LLM) or building a Text-to-Speech (TTS) engine, converting numbers into words is often the difference between a model that “understands” and one that fails.
1. The “Tokenization” Problem
Machine learning models don’t read words; they read “tokens.” When an AI encounters a number like $1,250$, it might break it down into four separate tokens: 1, ,, 2, and 50.
By normalizing this to “one thousand two hundred fifty,” you provide the model with a continuous linguistic string. This helps the AI understand the magnitude and context of the number within a sentence, leading to better semantic analysis.
2. Improving Text-to-Speech (TTS) Naturalness
If you have ever heard a robotic voice say “Total: one five zero zero dollars” instead of “Fifteen hundred dollars,” you’ve experienced poor normalization.
For developers building voice assistants or automated narration tools, numbers must be converted to text before being fed into the synthesis engine.
* Ambiguity: Should “1998” be read as a year (“Nineteen ninety-eight”) or a quantity (“One thousand nine hundred ninety-eight”)?
* Precision: Converting decimals and fractions into clear words ensures the synthetic voice sounds human and authoritative.
3. Data Cleaning for Sentiment Analysis
In sentiment analysis, the scale of a number can change the “weight” of a sentence.
* “I waited 5 minutes” (Neutral)
* “I waited 500 minutes” (Negative/Hyperbole)
Normalizing these digits into words helps the model associate specific word-patterns with intensity, improving the accuracy of emotional detection in customer reviews and social media monitoring.
4. Handling “Out-of-Vocabulary” (OOV) Errors
Many smaller machine learning models have a limited vocabulary. They might recognize the word “million,” but they may not have the specific digit “1,000,000” in their training set. By converting all numerical data into their word equivalents, you ensure the model stays within its known vocabulary, reducing the risk of “Out-of-Vocabulary” errors.
5. Standardizing Global Data Sets
As we’ve discussed in our guide on international numbering systems, comma placement varies globally. An AI trained on Western data might be confused by the Indian format $1,00,000$.
Normalizing these diverse formats into a standardized English word string (e.g., “one hundred thousand”) “flattens” the data, making it consistent and ready for training regardless of its origin.
Summary: The Developer’s Preprocessing Checklist
| Step | Task | Benefit |
|---|---|---|
| 1 | Identify Numerical Strings | Detects digits, currencies, and dates. |
| 2 | Number-to-Words Conversion | Converts symbols into linguistic tokens. |
| 3 | Remove Symbols | Cleans out commas, dollar signs, and percent marks. |
| 4 | Case Normalization | Ensures all text is lowercase for consistency. |